Outlines and TensorFlow playground


This writing might fall under more of a documentation. This is not covering general machine learning topic:
Course Context: Final assignment project for a Machine Learning course
Data Sources:
SEC insider transactions dataset: Predictor
Insights into stock transactions by company insiders.
Individual company stock prices: Target
Daily closing price of individual company stocks therefore the movements.
yfinance
NDXT (nasdaq100 technology sector index): Context
Complementary index
yfinance
Models: Linear regression and LSTM models
- Linear and non-linear relationships between variables and time dependencies
Objective: The primary goal is to find out if insider transactions in a company put any impact on the company's stock price. A possible correlation between insider transactions and a company's stock price might enable predicting market trends.
Expected Outcome:
Explain the correlation between insider transactions and a company's stock price
Account for general market trends
Make decisions based on the insight obtained
Limitations: Volatility and randomness in financial markets.
Study outline for the project (libraries):
Python: Basic syntax and components
Numpy: Multidimensional array objects and calculation operations
Pandas: Pandas manages and analyzes tabular data, similar to an Excel spreadsheet.
DataFrames, Series, importing and exporting data (CSV, Excel, SQL)
Operations: fillna, dropna, groupby, etc.
# Create new features or modify existing ones df['column'].apply(lambda x: x+2)# Grouping or aggregation df.groupby('column').mean()
Scikit Learn: Data preprocessing
- Scaling, Sequencing (Windowing), Splitting
TensorFlow/Keras
Loss Functions, Optimizers, Fitting, batch size, epochs, Validating, Evaluation metrics
# Specify the optimizer and loss function to use. model.compile(optimizer='adam', loss='mse')# Adjust the model's parameters. model.fit(x_train, y_train, batch_size=32, epochs=10, validation_data=(x_val, y_val))
Resources
- Google Colab, AWS, Azure, GCP
Study outline for the project (theories):
Linear Regression
LSTM
Recurrent Neural Networks (and Artificial Neural Networks all squashed into)
Time Series, forecasting, GRU and LSTM
Neural Networks and TensorFlow Playground
The concept of perceptron, layers, algorithms and big amounts of data are what brought the shift from traditional machine learning methods to deep learning.
Activation functions decide whether a node (neuron, perceptron) should be activated or not for the output. It adds non-linearity to the output as real-world data is non-linear so that nodes can learn these non-linear representations.
Some common activation functions are:
Sigmoid: The Sigmoid function takes any range real number and returns the output value which falls in the range of 0 to 1. It's not zero-centered which is a disadvantage.
Tanh: Tanh squashes a real-valued number to the range -1 to 1. It's zero-centered which makes it easier for model to learn.
ReLU (Rectified Linear Unit): The ReLU function is
f(x) = max(0, x). The output isxifxis positive and0otherwise. It's usually a default choice for many situations.Leaky ReLU: Leaky ReLU is a variant of ReLU with a small positive slope for negative input values, which prevents dead neurons.
The activation function used in a neural network model can be different for different layers, and ReLU is a good default choice for most of the cases.
Gradient descent algorithm finds the weight that minimizes the loss, and Backpropagation algorithm is used to quickly adjust these optimal weights. Backpropagation calculates the vector that points in the direction in which the model's parameters (weights and biases) need to be adjusted. It distributes the error with the output back through the layers.
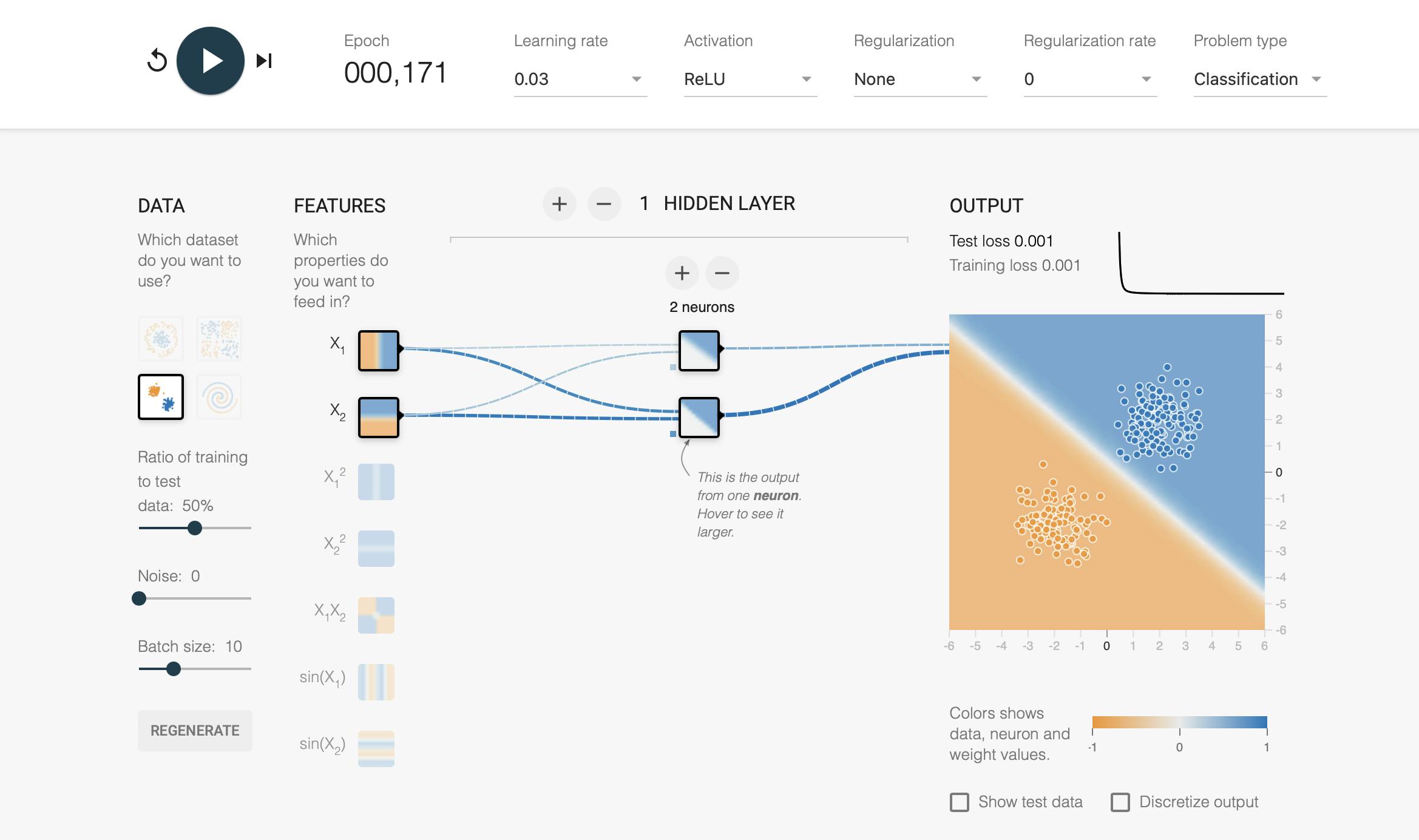
playground.tensorflow.org helps to try and understand these concepts. We can say that we're building a simple binary classification model that predicts house prices. We selected 2 features, X1 (the size of the house) and X2 (the number of rooms) and a hidden layer with 2 neurons (X1 and X2 are transformed in 2 different ways). The neural network will predict whether a house will sell for more than the price we set. The output would be the probability of this happening.
The activation function we use is ReLU and the playground trains the model with stochastic gradient descent. The Data has 2 separate clusters (third from the top left) and Features, Ratio of training to test data, Noise, Batch size, Learning rate are playground's defaults, Regularization is None and Problem Type is Classification:
Reference: https://www.udemy.com/course/complete-guide-to-tensorflow-for-deep-learning-with-python/