Articles in this series
K-means clustering is a type of unsupervised machine learning algorithm. Unlike supervised learning (like regression or classification) where you have...
In k-means clustering, a data point refers to an individual record in the dataset. In this case, a data point corresponds to a customer's shopping...
We've completed the data preparation stage, where we have cleaned the data, processed it to get desired features, and understood the data to some...
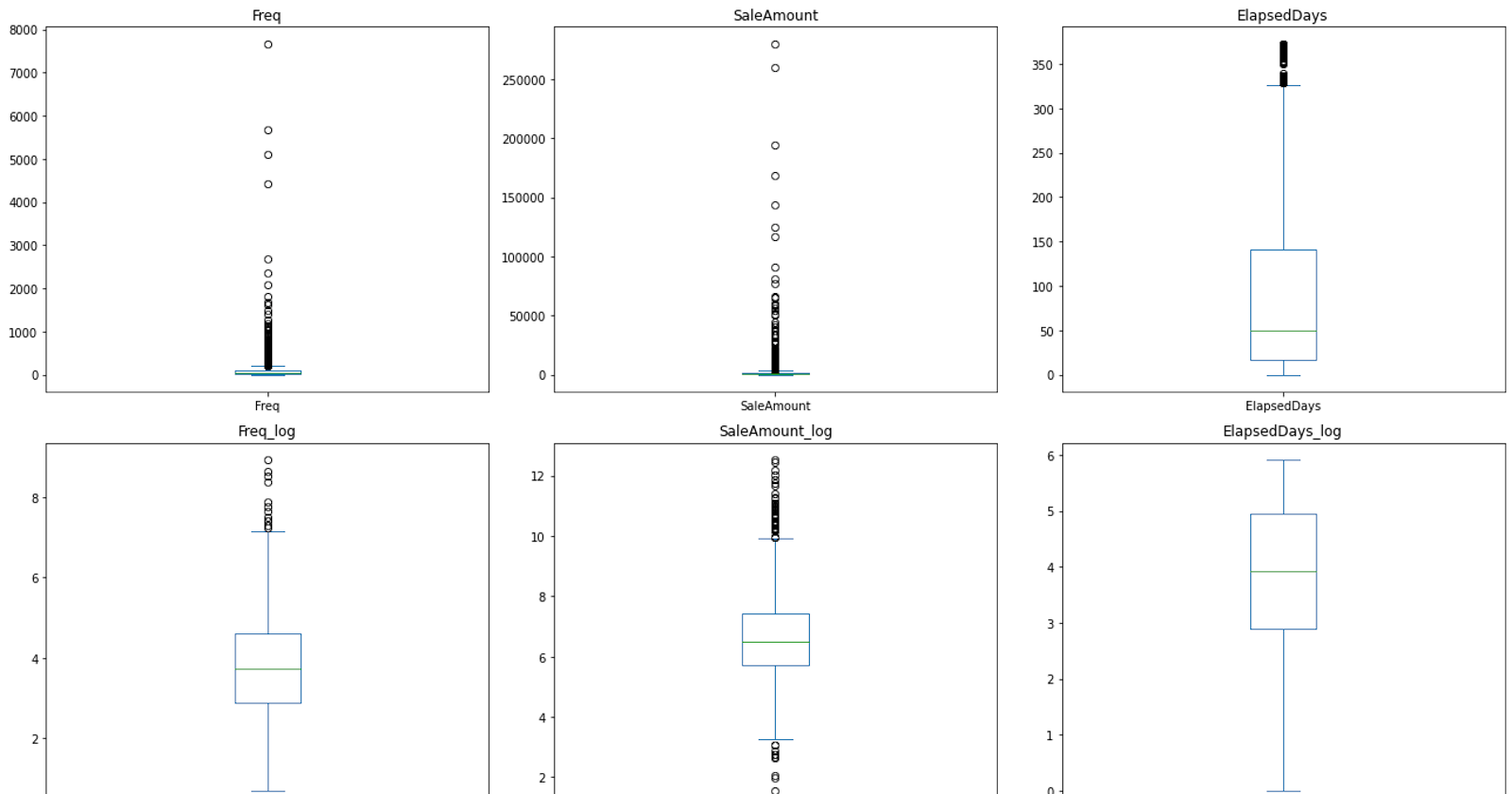
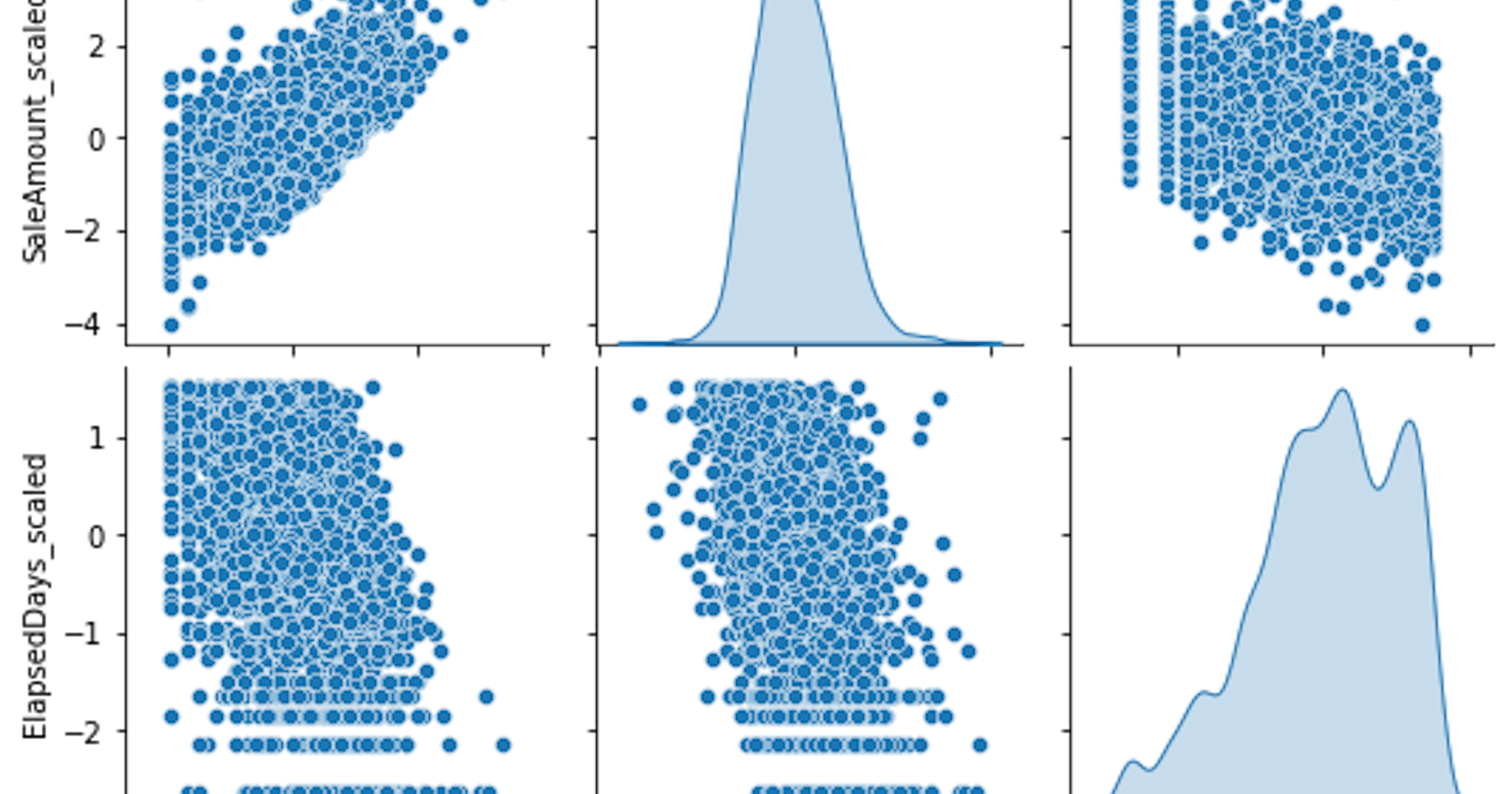
We've now completed the data preprocessing and transformation stage. Data visualization is an excellent way to understand the properties and trends of...
from sklearn.cluster import KMeans scaled_df, X_features Out: ( Freq_scaled SaleAmount_scaled ElapsedDays_scaled 0 -2.438202 ...
To evaluate how well the clustering worked, we can calculate the silhouette score, which is a measure of how similar an object is to its own cluster...